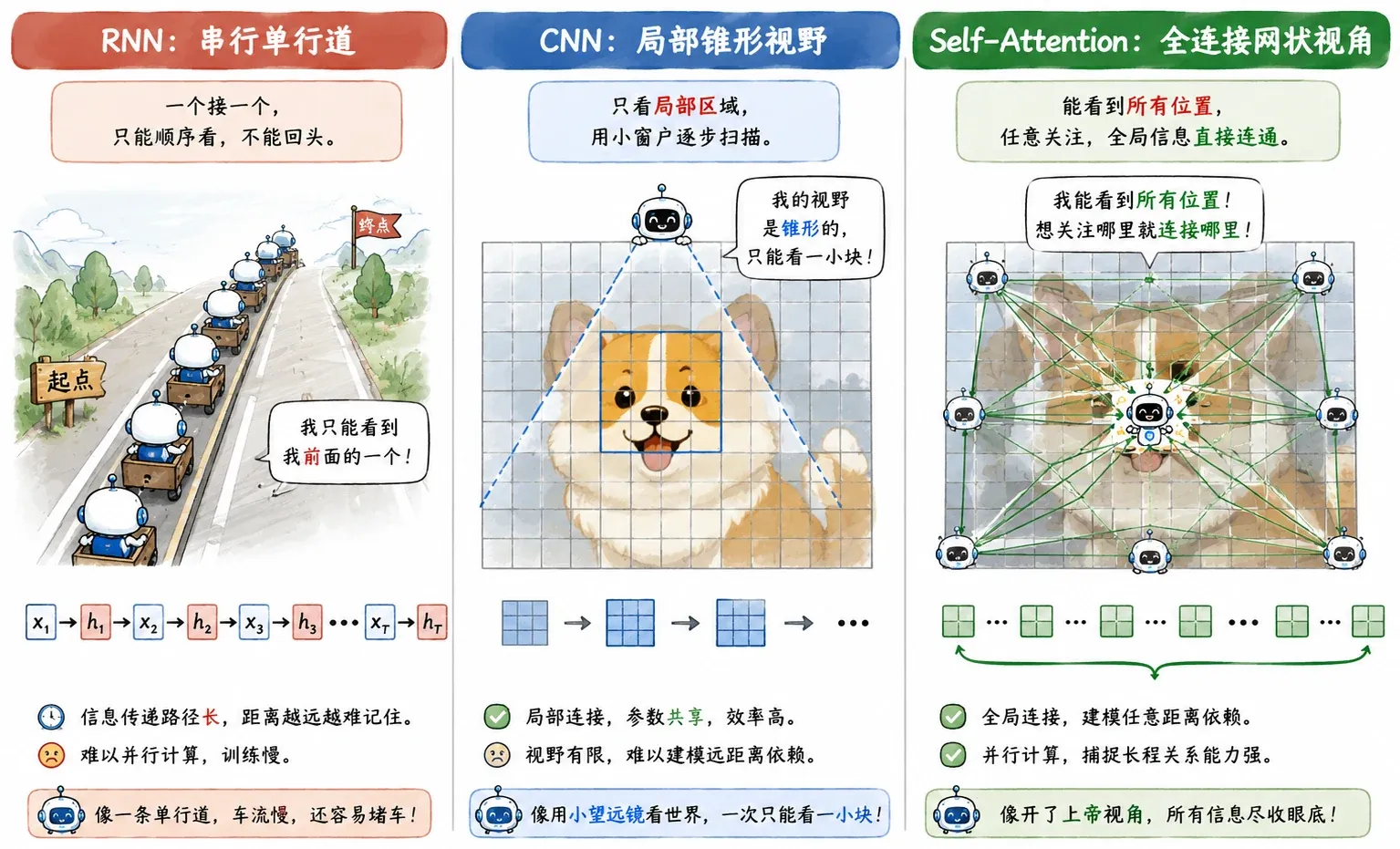
相比 RNN 在单行道上排队传递情报,Transformer 直接在广场上拉起了一张全连接的无死角通讯网。
加速,加速,加速!
天下武功,唯快不破
RNN 的硬伤已经是老生常谈了,串行计算效率低下,就算在工程中提出了并行策略,但根本的数据依赖没有解决。
要算 h2,就必须老老实实等 h1 算完;要算 h3,又得等 h2。这对 GPU 来说,完全折磨。
中间也有人尝试过用 CNN 来处理文本。卷积的好处是能大面积并行,抓取局部短语特征也很拿手。但语言存在长距离依赖(Long-term Dependency),CNN 受限于局部的感受野,想要让句子首尾的词建立联系,就必须堆叠极深的网络层数。信息在层层传递中,早就发生了损耗。
就在这个关键时刻,Self-Attention(自注意力机制) 登场了。
Transformer 证明了:仅仅依靠 Attention,完全抛弃 RNN 和 CNN 的复杂架构,也能完成最顶级的序列建模。
它带来了一个降维打击—— O(1) 的路径长度:
句子里的每一个词,在同一层里,直接跨越空间限制,和全场所有的词进行全连接交流。
从信息传递路径来看,RNN 计算一个长度为 n 的序列,信息传递的路径长度是 O(n);而 Self-Attention 一步到位,路径长度永远是 O(1)。当然,全连接也意味着一个 O(n2) 的庞大注意力矩阵。这成为了后来长上下文模型、FlashAttention 甚至 DiT 架构在降低 Token 成本时必须跨越的一道天堑。
QKV
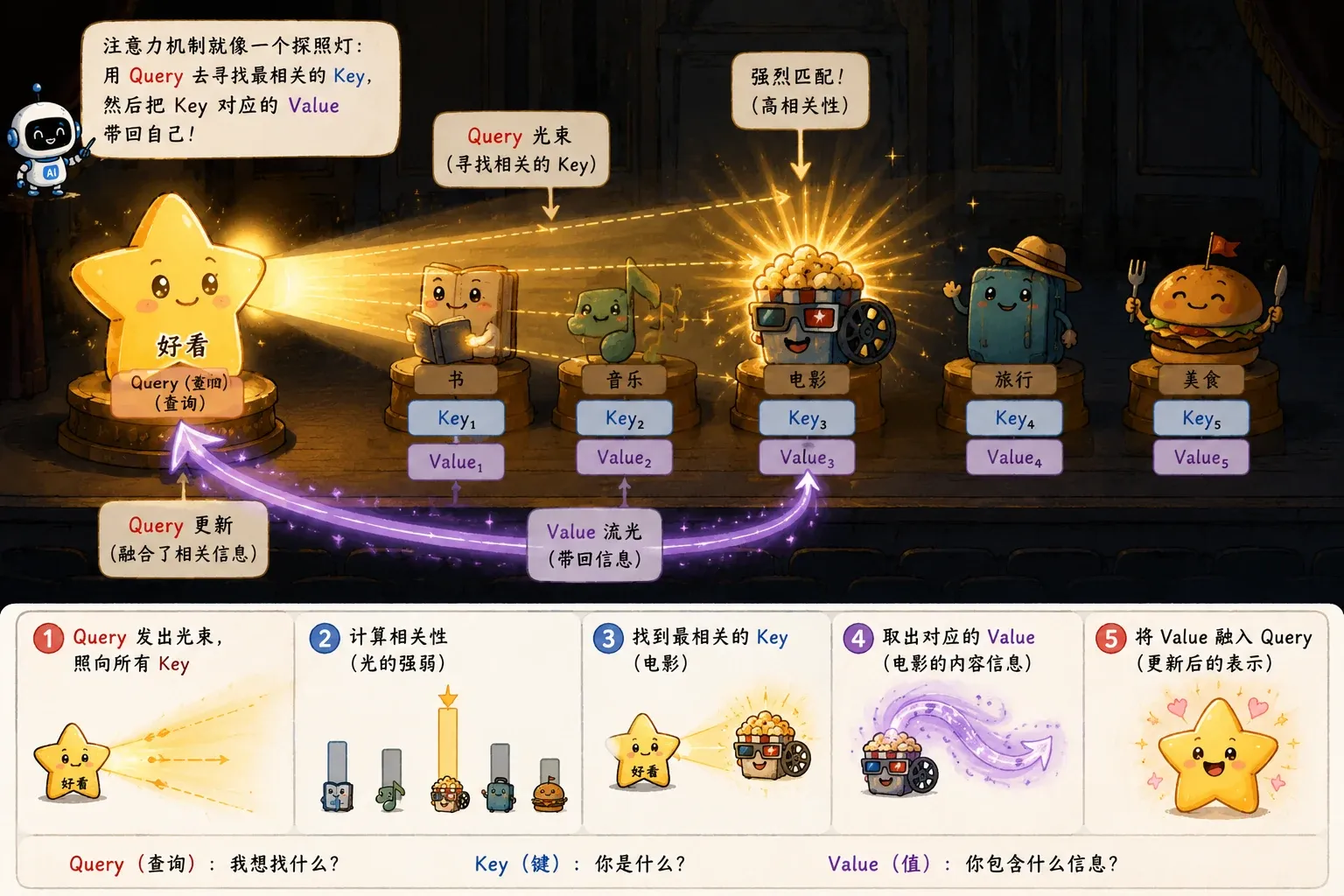
什么是 QKV?
Self-Attention 的核心引擎由三个向量驱动:
- Query (Q): 我要找什么。
- Key (K): 每条内容的索引标签。
- Value (V): 每条内容真正携带的信息。
这套逻辑其实就是现代数据库检索系统的翻版。会有疑问,既然是 Self-Attention,为什么不直接拿词向量 X 互相点积?
答案在于打破对称性并引入可学习参数。直接用同一表示做匹配会限制表达能力,Q/K/V 分离让“查询角色”“被检索角色”和“内容载体”可以分别学习。
因此,我们引入了三个不同的权重矩阵 WQ,WK,WV,把同一个输入 X 投影到三个不同的特征空间中:
Q=XWQ,K=XWK,V=XWV
最后我们终于得到了那个印在深度学习教科书首页的终极公式:
Attention(Q,K,V)=softmax(dkQKT)V
数学推导
假设句子有 4 个词(T=4),单头注意力维度 dk=64。
-
QK⊤:计算两两匹配相似度
Q=[T,dk]=[4,64]
q1(1)q2(1)q3(1)q4(1)q1(2)q2(2)q3(2)q4(2)…………q1(64)q2(64)q3(64)q4(64)
- 第 1 行:第 1 个词的完整查询向量 q1∈Rdk,共 64 个元素
- 第 2 行:第 2 个词的查询向量 q2∈Rdk
- ……
K⊤=[dk,T]=[64,4]:
k1(1)k1(2)⋮k1(64)k2(1)k2(2)⋮k2(64)k3(1)k3(2)⋮k3(64)k4(1)k4(2)⋮k4(64)
矩阵相乘 QK⊤ 输出相似度分数矩阵,尺寸 [T,T]
S=QK⊤,shape [4,4]s1,1s2,1s3,1s4,1s1,2s2,2s3,2s4,2s1,3s2,3s3,3s4,3s1,4s2,4s3,4s4,4
(i,j):第 i 个查询 token qi,和第 j 个键 token kj 的匹配程度。
-
dk:缩放操作
可以压缩点积的数值波动范围;在独立同分布假设下,点积方差约为 dk,缩放后方差回到约 1,使得 Softmax 输出的权重分布更均匀,全程保留可更新的梯度。
-
softmax(⋅):归一化
对相似度矩阵每一行单独做 softmax,保证每行权重加和为 1,得到注意力权重矩阵 α:
α11α21α31α41α12α22α32α42α13α23α33α43α14α24α34α44
αi,j=softmax(dkqikj⊤)
αi,j:解码/编码第 i 个词时,分配给第 j 个输入 token 的关注权重。
-
V:加权求和
权重矩阵 α 乘以值矩阵 V∈[T,dk]:
Attention(Q,K,V)=αV
取第 2 行看:
[α21, α22, α23, α24]
代表第 2 个词,分配给 4 个词的关注度权重。
计算输出向量:
output2=α21v1+α22v2+α23v3+α24v4
对应通用公式:
outputi=j=1∑Tαi,j⋅vj=ci
即对所有 vj 按注意力加权求和,生成只属于第 i 个 token 的专属上下文向量。
实例演示
我们拿一句大白话来看看:
这 部 电影 很 好看
模型算到“好看”时,它的 Query 会去全场扫射:
- 匹配“这”,分数极低;
- 匹配“部”,分数极低;
- 匹配“电影”,Bingo!分数飙高。
于是,“电影”这个词携带的 Value,就会被赋予极大的权重,像调色一样被融进“好看”的新表示里。经过这一层,原本干瘪的“好看”,就变成了一个富含上下文的“修饰电影的好看”。
而且这套规则完全不需要人工干预。
用来做乘法的 WQ,WK,WV 矩阵,全都是模型自己在成百上千亿的语料库里“炼”出来的。它会自己学会到底该关注语法搭配,还是关注情感修饰。
矩阵并行化
Self-Attention 真正改变深度学习时代的命门,在于它可以是纯粹的矩阵运算,一切都被打包成了超级大的矩阵乘法:
- X×W,算出全场所有词的 Q,K,V。
- Q×KT,得到所有词两两之间的 Attention 棋盘。
- 再乘上 V,完成所有权重的加权融合。
这是 Transformer 能吃下海量参数、海量数据,并最终引爆 LLM 狂潮的硬件底座。
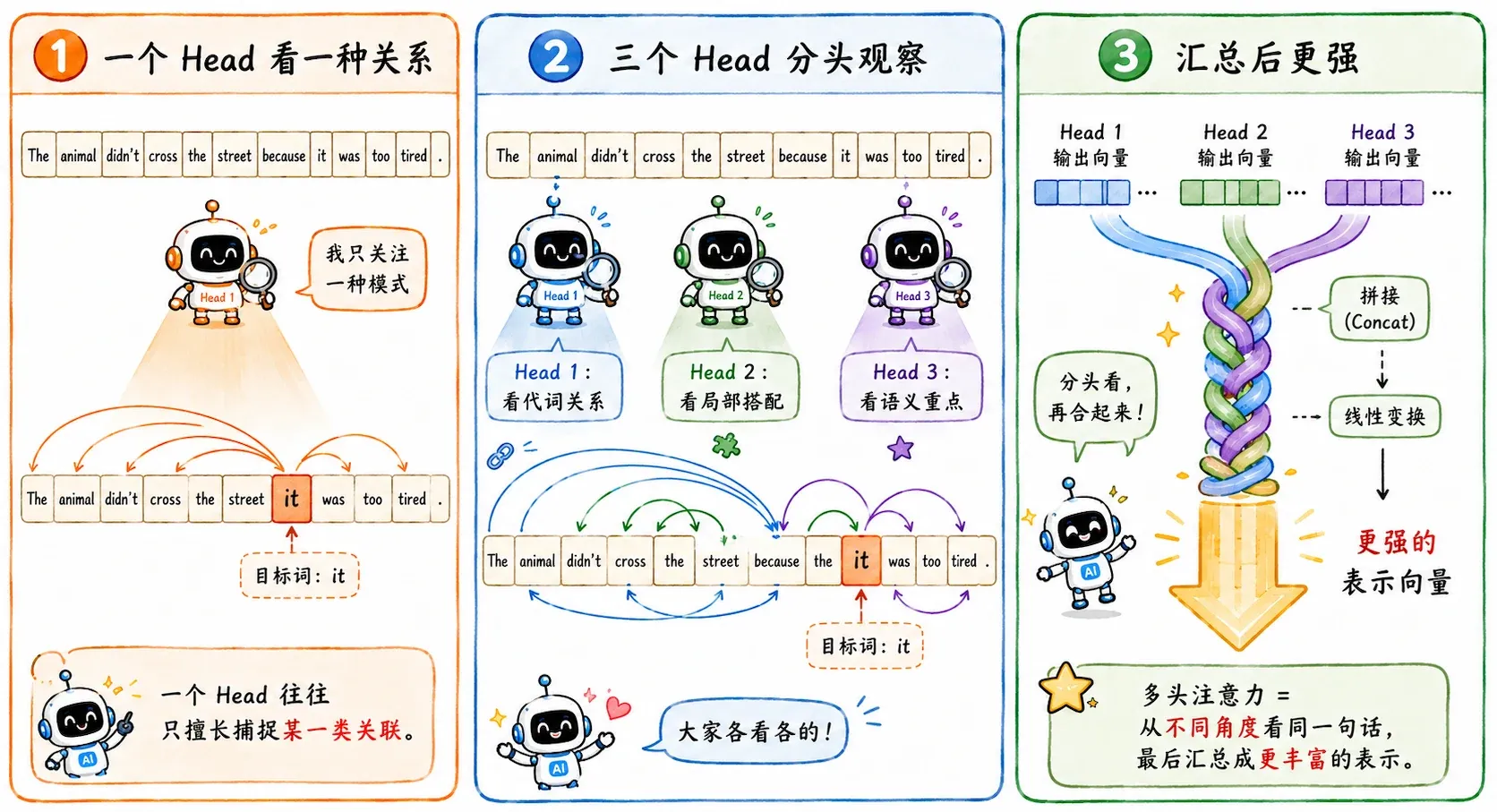
Multi-Head
单 Attention 头是有局限的,它只能在某一种特定的情感/语义空间里去做匹配。
同样是“电影”和“好看”,在一个维度里它们是主谓关系;在另一个维度里可能都是属于“娱乐”范畴的词。
Multi-Head Attention(多头注意力) 同时维护多组(假设为 h 组)完全独立的 QKV 投影矩阵。每个 Head 在各自的子空间里计算 Attention:
headi=Attention(XWiQ,XWiK,XWiV)
每个 Head 各自算完之后,大家把结果沿着特征维度拼在一起(Concat),最后再过一个线性层(WO)整合出最终的输出:
MultiHead(X)=Concat(head1,…,headh)WO
位置编码
Self-Attention 这么神,但有一个硬伤:本质是不辨方向的词袋。
如果只把词丢进那个 QKV 的公式里互换眼神,那对模型来说,“我喜欢你”和“你喜欢我”是完全等价的,因为参与打分的 Token 一模一样。
为了不让网络变成文盲,Transformer 被迫引入了一个外挂装置:Positional Encoding(位置编码)。
在单词变成 Embedding 送进网络之前,原论文使用不同频率的正弦和余弦函数,为每一个位置生成了一串唯一的坐标向量:
PE(pos,2i)=sin(100002i/dmodelpos)
PE(pos,2i+1)=cos(100002i/dmodelpos)
其中 pos 是单词在序列中的绝对位置,i 是维度的索引。偶数维度(2i)使用 sin,奇数维度(2i+1)使用 cos。
模型通过多组不同频率的周期信号组合实现了位置信息编码。低维分量对应高频信号,能够捕捉局部微小位置变化;高维分量对应低频信号,用于感知全局相对位置。加上位置编码后,模型才终于拥有了立体的方向感。
(注:Jay Alammar 的 The Illustrated Transformer 做了很好的可视化,可以学习关于 QKV 和位置编码的动画演示。)