深度学习 10
GNN 基础1
生成模型基础4
Transformer 基础3
这些训练技巧在调整训练过程的节奏、噪声和尺度。
三类技巧
除开前面已经讲过几类训练问题与解决方案,还有一些工程上的技巧。
可以大致分成三类:
- 增加随机性:平滑损失空间,鼓励模型探索(Exploration)。
- 训练节奏控制:调整学习率和数据分布难度,避免早期震荡。
- 尺度约束:控制数据、中间激活值与梯度的数值范围,避免爆炸或消失。
增强随机性
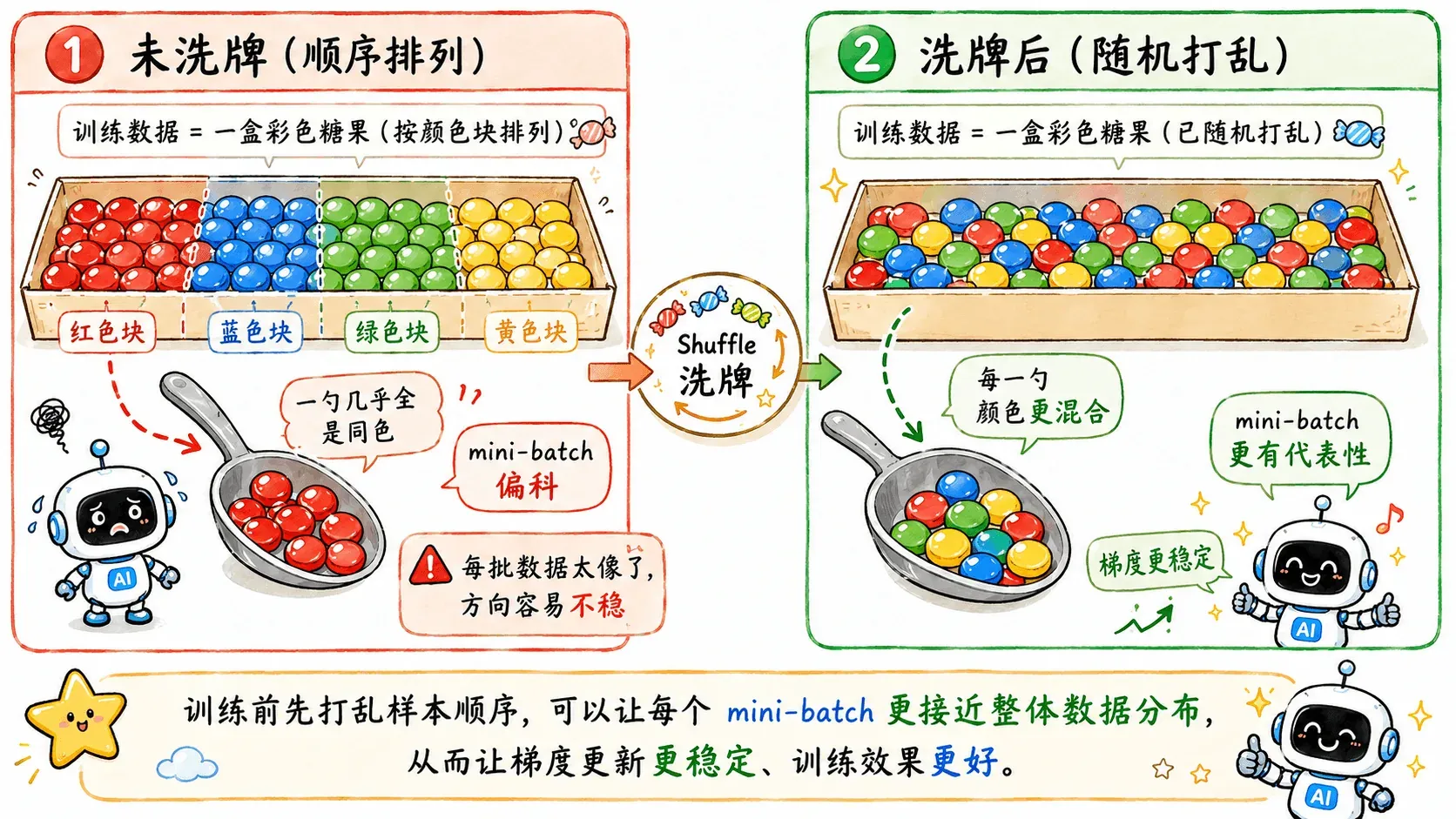
数据洗牌(Shuffling)
如果训练数据按类别连续排列,模型在特定阶段只会计算出单一方向的梯度,导致优化轨迹严重偏离全局最优,甚至陷入局部特化。
随机洗牌确保了每个 mini-batch 的数据分布尽可能接近全局数据集的真实分布,使得梯度的期望方向更加稳定。
梯度噪声(Gradient Noise)
在计算出的真实梯度上,显式叠加一个服从高斯分布的噪声:
公式拆解:
- :当前 mini-batch 计算得出的原始梯度。
- :随时间步 衰减的噪声方差。通常采用 的退火策略。
核心逻辑:深度神经网络的损失(Loss)空间极度非凸,充满局部最优和鞍点(Saddle Point)。叠加高斯噪声等价于对损失空间进行平滑化,使得优化器在陷入平缓区域时,仍能获得足够的动量跳出局部陷阱。随着训练深入,模型逼近收敛,噪声方差逐渐归零。
训练节奏控制
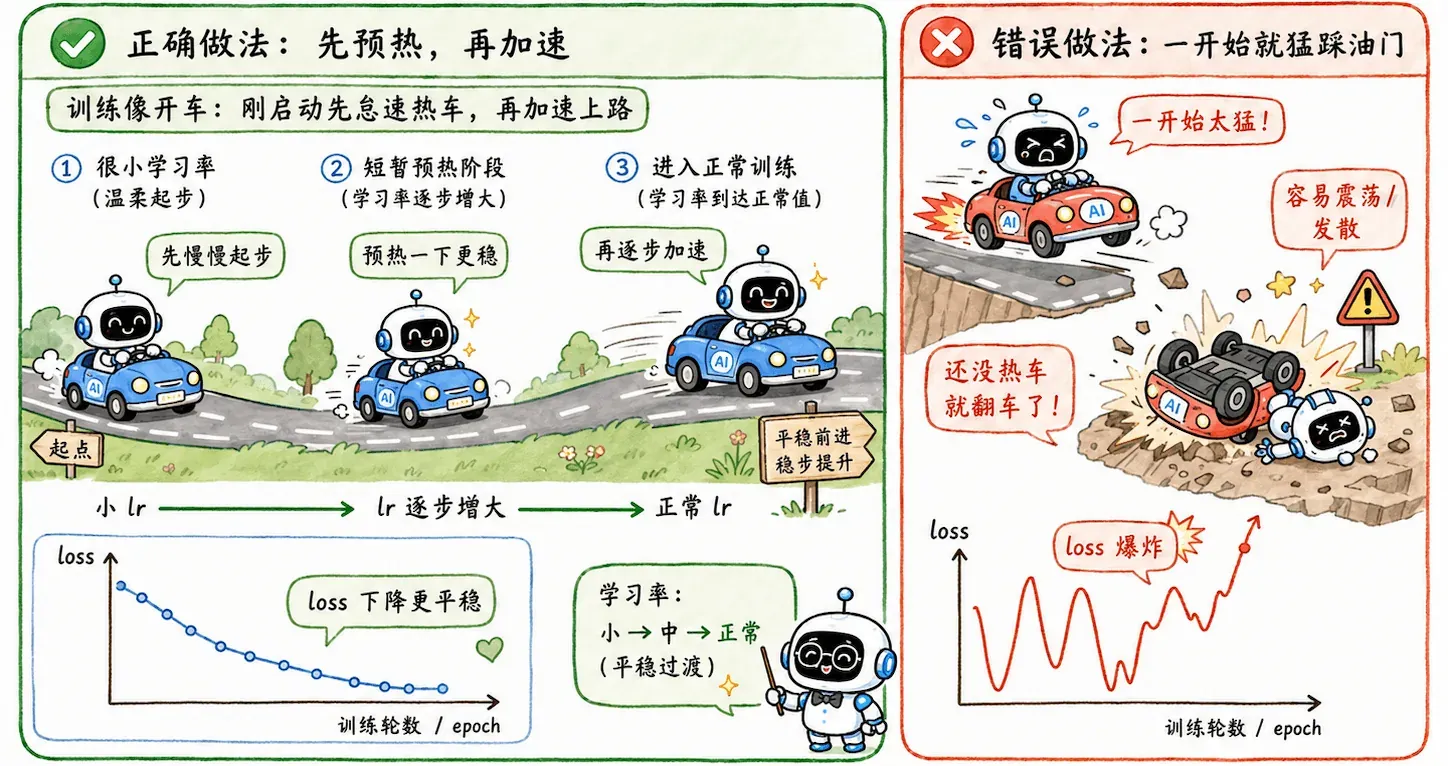
学习率预热(Warmup)
训练初期,网络权重处于随机初始化状态,且优化器(如 Adam)的动量统计量尚未建立。如果直接使用较大的初始学习率,会产生剧烈的梯度更新,瞬间破坏网络参数分布。
Warmup 的操作非常简单:在前 个 epoch 或 step 中,将学习率从一个极小值(或 )线性递增至预设的基准学习率。这给了优化器收集稳定一阶/二阶动量的缓冲期。
课程学习(Curriculum Learning)
调整数据的输入难度。
训练初期使用特征清晰、背景干净的“简单样本”,帮助模型快速确立基础决策边界;随着训练推进,逐渐混入遮挡、噪声严重、边缘模糊的“困难样本”。这种自适应的数据喂入策略能显著提升模型的最终鲁棒性。
微调(Fine-tuning)
相比从零初始化(Train from scratch),拿一个在大规模泛化数据集上预训练过的权重作为起点,收敛速度更快,且不易在小数据集上过拟合。
核心痛点是灾难性遗忘(Catastrophic Forgetting)。为了保护预训练模型中已有的高质量底层特征,微调通常需要搭配极其微小的学习率,或者直接冻结(Freeze)浅层网络,只更新顶层分类器。
归一化(Normalization)
网络变深带来的致命问题是:内部协变量偏移(Internal Covariate Shift)。 第一层参数微小的更新会被层层放大,导致高层网络每次都在面对剧烈变化的输入分布。归一化的目标是将中间激活的分布强制拉回稳定尺度。
批归一化(BatchNorm)
将维度粗略想成一张表:行是样本,列是特征。BatchNorm 是按列归一化。
对第 个特征,拿当前 mini-batch 中所有 个样本进行统计:
拉回标准正态分布:
最后乘以可学习缩放参数 ,加上平移参数 :
为什么需要 和 ? 强制均值为 0、方差为 1 可能会破坏特征本身的表达能力(比如 ReLU 函数前的非负特征如果被强制拉平,会损失一半的激活空间)。 和 将“是否需要保留原始分布”的控制权交还给网络去学习。
注:BN 极度依赖 Batch Size。且训练时使用当前 Batch 的统计量,推理时使用全局移动平均(Running Mean/Var)。
层归一化(LayerNorm)
LayerNorm 是按行归一化。
只看当前第 个样本内部的全部 个特征:
LN 不依赖 Batch 中的其他样本,因此在 Transformer 等处理变长序列的场景中占据统治地位。
对于输入张量 (Batch, 序列长度, 隐藏层维度),LayerNorm 通常独立作用于最后的 维。
维度切片直观对比
无论是 BN、LN 还是 InstanceNorm,底层数学都一样,区别仅仅在于“参与计算 和 的数据切片范围”。
其他 Norm
- InstanceNorm:更常见于风格迁移,倾向于单张图片、单个 channel 内部做归一化。
- GroupNorm:把 channel 分组后归一化,常用于 batch size 很小、BatchNorm 不稳定的视觉任务。
- RMSNorm:可以看成 LayerNorm 的简化版本,不减均值,只按均方根缩放,很多 LLM 会使用。
尺度与自由度约束
除了数据本身的归一化,训练稳定性还需要直接干预梯度和模型参数的规模。
梯度裁剪(Gradient Clipping)
在面临悬崖般的陡峭 Loss 空间时(常见于早期的 RNN),一次巨大的梯度反向传播会直接把参数推向 NaN,导致训练直接崩溃。
梯度裁剪是对抗梯度爆炸的最粗暴且有效的手段。计算出整个参数层的梯度范数(L2 Norm):
公式拆解:
- :原始梯度矩阵。
- :梯度的 L2 范数(大小)。
- :预设的阈值上限。
核心逻辑:只限制梯度的最大长度,不改变梯度的方向。确保参数更新的步伐始终在一个安全范围内。
正则化(Regularization)
正如前文在 L2 与 Dropout 中所述,正则化是从损失函数的角度对模型施加“紧箍咒”。
- L2 正则化(Weight Decay):在 Loss 后附加参数的平方和惩罚项 ,迫使模型使用分布更均匀、数值更小的权重矩阵,避免对个别噪声特征产生极端依赖。
- Dropout:每次前向传播时,按概率 随机将神经元置零:。这物理性地切断了特定神经元之间的固定共适应(Co-adaptation),迫使网络在残缺的路径上也能提炼出鲁棒特征。