深度学习 01
GNN 基础1
生成模型基础4
Transformer 基础3
感知机本质上还只能算一个线性模型,处理不了非线性的问题。
多层感知机提出了特征变换,有效地突破了局限。
从感知机开始
何为感知机
1958 年,心理学家 Rosenblatt 提出了感知机。这可以看作是神经网络的 V1.0 版本。
感知机这个名字听起来怪吓人的,其实底层逻辑很简单:拿输入 乘上一组权重 ,加上偏置 后再做一个判断:
- 若 成立,输出 。
- 若 不成立,输出 。
在二维平面上考虑,感知机就相当于一个裁判画一条直线,把样本分置两侧。
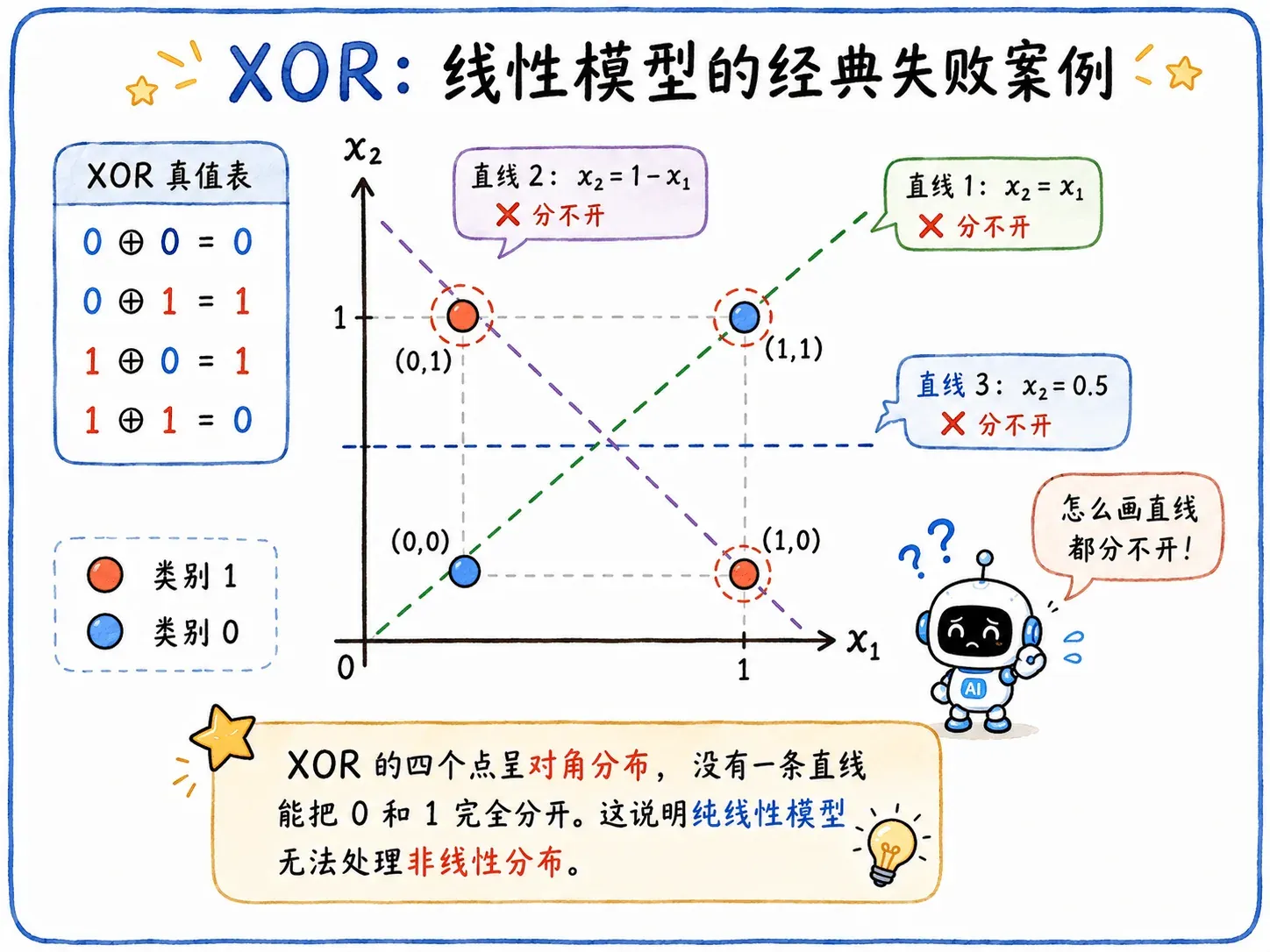
XOR 问题
1969 年,Minsky 和 Papert 在《感知机》一书中指出了感知机的一个重要局限:只能处理线性可分问题。
最经典的失败案例就是异或问题:
- 两个输入相同,输出 。
- 两个输入不同,输出 。
在二维平面上选取四个代表点:
没有一条直线能把输出 0 和 1 的坐标分开!
多重感知机
基本概念
1980 年代,研究者们提出多重感知机 MLP。其实就是借助多级隐藏层,实现了非线性数据的特征变换。
既然原空间里处理不了非线性数据,那就干脆改变空间。
特征变换
原来的 空间里,XOR 无法划分。但如果我们让中间层学出两个新的特征:
最后一层就可以在 空间中实现划分了:
神经网络结构
一个最简单的神经网络,可以大致分为三部分:
- 输入层(Input Layer)
- 隐藏层(Hidden Layers)
- 输出层(Output Layer)
输入层
输入层虽然带个“层”,但其实际上就是指给模型的输入,并不是什么真正的“层”。
比如图片任务里输入就是像素;表格任务里输入就是一组特征;文本任务里输入就是一串 token。
也可以把这一层理解为原始数据进入模型的接口/通道。
隐藏层
隐藏层是输入层和输出层之间的层。
Deep Learning 中的 Deep 即指多个隐藏层叠加,不过多少层才算 Deep,并没有统一标准。
隐藏层可以看成特征提取器,作用是代替特征工程。
之前的很多任务都依赖人工设计特征:比如做房价预测,我们要先想清楚面积、楼层、地段这些变量怎么组织;做图片识别,又要先想清楚边缘、纹理、颜色这些特征怎么处理。
这些事情交给神经网络的隐藏层来处理就很简单了:
让隐藏层自我学习分类前应该怎么改造特征。
也就是说,模型前面的层不断把原始输入变成新的表示,后面的层再拿这些表示做判断。
输出层
输出层是最后一层。
它可以看成分类器,也可以看成回归器,这取决于任务本身需要什么输出。
如果是分类任务,输出层可能给出每个类别的分数,再交给 Softmax 变成概率;如果是回归任务,输出层可能直接给出一个连续值。
总而言之,神经网络干的事就是:
激活函数
当然,不是说只要把模型改造成多层结构,模型就能解决非线性问题了。一个很显而易见的问题:即使是多层网络,如果每一层都只是线性变换:
那最后合并一看,本质还是一个线性变换函数(白忙活):
所以关键在于每一层之间必须插入非线性激活函数,比如早期常用的 Sigmoid:
激活函数可以有效的对空间进行折叠、弯曲或截断,让每一层的输出真正实现了特征变换。
不过 Sigmoid 作为最早期的激活函数,存在很多不足,后人提出了很多优化方案。
深度学习框架
学到这里不难发现,深度学习仍然是机器学习的底层框架:
- 确定模型(Model)/函数集(Function Set)
- 确定如何评价函数的好坏
- 确定如何找到最好的函数
只是在深度学习里,模型是更复杂的多层函数组合。
确定模型
在深度学习中,确定模型就是定义一个神经网络。不同的神经元连接方式会构成多样的网络结构。
全连接层(FNN)是一种结构,后面会学到的 CNN、RNN、Transformer 也是。它们都遵循机器学习的流程,区别只在于怎么组织函数、怎么让参数共享、怎么适配不同形态的数据。
确定评价标准
第二步还是定义 Loss,思路也一样,把模型好不好变成一个可以优化的数字(量化)。
有了 Loss,才能用梯度下降来更新参数。
找到最好的函数
第三步还是 Gradient Descent。
神经网络模型对应的函数比较复杂,而反向传播算法是一个很有效的计算神经网络梯度的方法。